csc 510-001, (1877)
fall 2024, software engineering
Tim Menzies, timm@ieee.org, com sci, nc state
home :: syllabus :: corpus :: groups :: moodle :: license

Fundamentals
erz.py is a few hundred lines of a simple AI script that demonstrates many important fundamentals of SE and AI.
- Students of AI/SE should browse the AI/SE sections (below)
1 Before We Start….
Macro structure of ezr.py:
- Starts with doc string, from which we parse out the control settings.
- Ends with a set of examples in the
egsclass which can be called from the command line. E.g.-e mqscalledegs.mqs(). - Uses a a function-oriented style, where methods are grouped by name, not class.
Terminology (watch for these words):
- Classes:
- SETTINGS, DATA, COLS, NUM, SYM
- Variables:
- row, rows, done (which divides into best and rest); todo
- SE Notes:
- refactoring, five lines, DRY, WET
- styles, patterns, idioms, function-oriented
- decorators, little languages, configuration, pipes, iterators, exception handling,
- make, regular expressions,
- decorators, type-hints, comprehensions, dunder methods,
- exception handling.
- AI Notes:
- Y, dependent, X, independent, goals,
- labelling, active learning,
- multi-objective, aggregation function, chebyshev
- explore, exploit, adaptive, acquisition function, cold-start, warm-start, diversity, perversity,
- (population|surrogate|pool|stream)-based
- model-query synthesis
- regression, classification, Bayes classifier,
- entropy, standard deviation
- over-fitting, order effects, learner variability, cross-validation, temporal validation
- Synonyms (conflations, to be aware of):
- features, attributes, goals
- Y goals dependent
- X independent
- styles, patterns, idioms
2 Overview
2.1 EZR is an active learning
The human condition is that we have to make it up as we go along. Active learning is a strategy for acting with partial knowledge, before all the facts are in.
To understand this, suppose we wanted to learn some model \(f\)
\[Y_1,Y_2,...\;=\;f(X_1,X_2,X_3....)\]
Any example contains zero or more \(X\) and \(Y\) values
- If there are no \(Y\) values, we say the example is unlabeled.
- If the model is any good then there must be some connection between
the \(X\)s and the \(Y\).
- This means we can explore the \(X\) space to build a loosey-goosey approximate of the \(Y\) space.
- It is usually harder (slower, more expensive) to find the \(Y\)s than the \(X\)s. For example,
- If we want to buy a used car then a single glance at a car lot tells us much about hundreds of car make, model, color, number of doors, ages of cars, etc (these are the \(X\) values)
- But it takes much longer to work out acceleration or miles per hour (these are the \(Y\) values) since that requires you have to drive the car around for a few hours.
2.2 SE Examples where finding \(X\) is cheaper than \(Y\)
- \(X\),\(Y\) are our independent and dependent variables.
- Quick to mine \(X\) GitHub to get
code size, dependencies per function,
- Slow to get \(Y\) (a) development time, (b) what people will pay for it
- Quick to count \(X\) the number of
classes in a system.
- Slow to get \(Y\) an organization to tell you human effort to build and maintain that code.
- Quick to enumerate \(X\) many
design options (20 yes-no = \(2^{20}\)
options)
- Slow to check \(Y\) those options with the human stakeholders.
- Quick to list \(X\) configuration
parameters for the software.
- Slow to find \(X\) runtime and energy requirements for all configurations.
- Quick to list \(X\) data miner
params (e.g. how many neighbors in knn?)
- Slow to find \(Y\) best setting for local data.
- Quick to make \(X\) test case
inputs using (e.g.) random input selection
- Slow to run all tests and get \(Y\) humans to check each output
2.3 Smart Labeling
- Learning works better if the learner can pick its training data[^brochu].
- Labeling is the process of finding the \(Y\) values, before we know the \(f\) function
- So we have to do something slow and/or expensive to find the label;s; e.g. ask an expert, go hunt for them in the real world.
- The first time we find the \(Y\) values, that incurs a one-time cost
- After that, the labels can be access for free.
- Just for simplicity, assume we a model can inputs \(X\) values to predict for good \(g\) or bad \(b\):
| n | Task | Notes |
|---|---|---|
| 1 | Sample a little | Get a get a few \(Y\) values (picked at random?) |
| 2 | Learn a little | Build a tiny model from that sample |
| 3 | Reflect | Compute \(b,r\) |
| 4 | Acquire | Label an example that (e.g.) maximizes \(b/r\) then it to the sample. |
| 5 | Repeat | Goto 2 |
So, an active learner tries to learn \(f\) using a lot of cheap \(X\) values, but very few \(Y\) values– since they are more expensive to access. Active learners know that they can learn better (faster, with fewer \(Y\) values) if they can select their own training data:
- Given what we have seen so far…
- Active learners guess what is be the next more informative \(Y\) labels to collect..
- Guidied by some acquisition function. E.g. in the following, “solid” is our guess of the mean, “dots” are the observations made so far, “purple” is the uncertainty, “green” is the acquisition function.
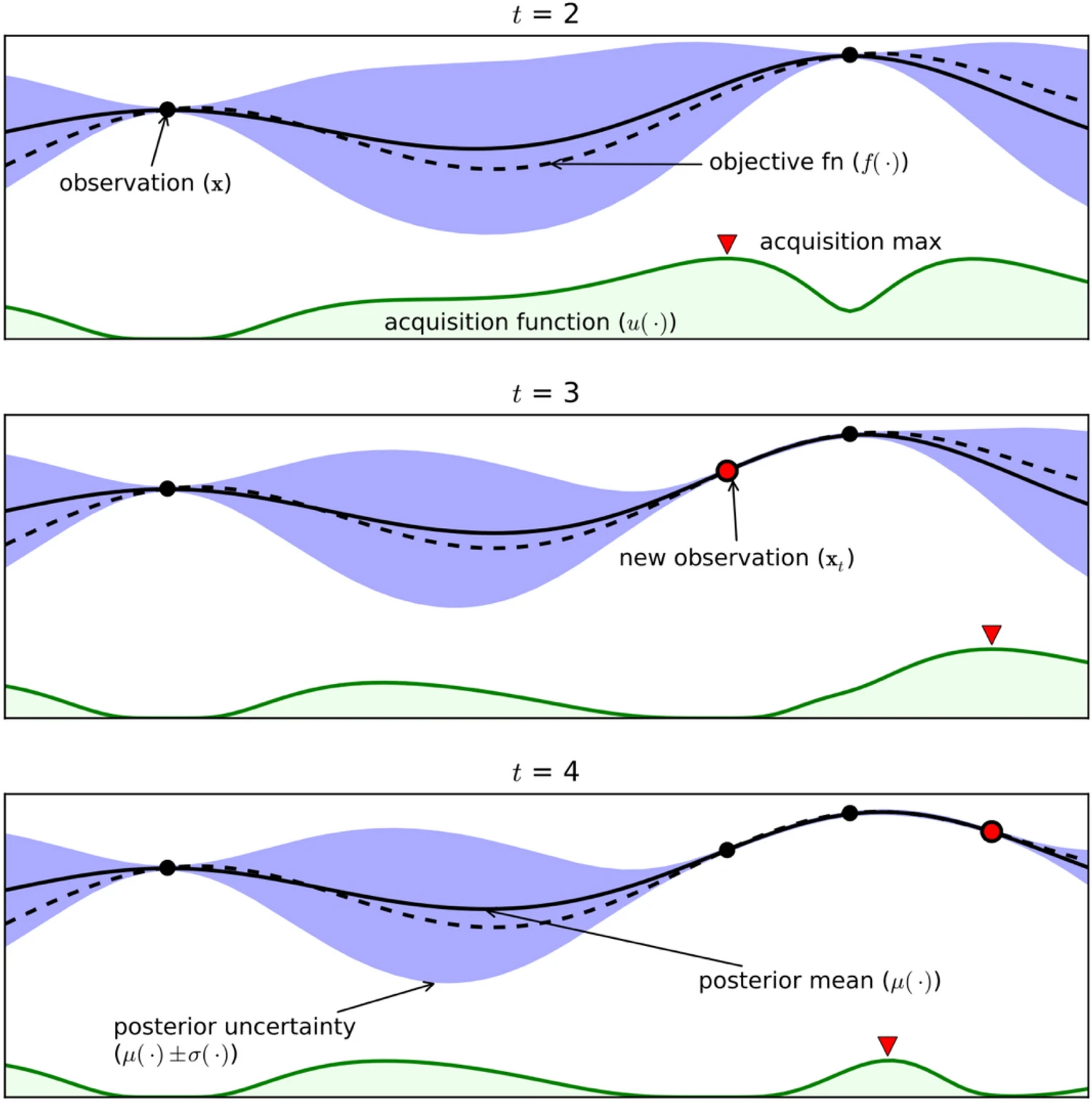
2.4 Training Data
Active learners spend much time reasoning about the \(X\) values (which are cheap to collect) before deciding which dependent variables to collect next. A repeated result is that this tactic can produce good models, with minimal information about the dependent variables.
For training purposes we explore all this using csv files where “?” denotes missing values. Row one list the columns names, defining the roles of the columns:
- NUMeric column names start with an upper case letter.
- All other columns are SYMbolic.
- Names ending with “+” or “-” are goals to maximize/minimize
- Anything ending in “X” is a column we should ignore.
For example, here is data where the goals are
Lbs-,Acc+,Mpg+ i.e. we want to minimize car weight and
maximize acceleration and maximize fuel consumption.
Clndrs Volume HpX Model origin Lbs- Acc+ Mpg+
------- ------ --- ----- ------ ---- ---- ----
4 90 48 78 2 1985 21.1 40
4 98 79 76 1 2255 17.7 30
4 98 68 77 3 2045 18.4 30
4 79 67 74 2 2000 16 30
...
4 151 85 78 1 2855 17.6 20
6 168 132 80 3 2910 11.4 30
8 350 165 72 1 4274 12 10
8 304 150 73 1 3672 11.1 10
------------------------------ ----------------
independent features (x) dependent goals (y)Note that the top rows are better than the bottom ones (lighter, faster cars that are more economical).
- Multi-objective learners find a model that selects for the best
rows, based on multiple goal.s
- Aside: most learners support single objective classifiers (for one symbolic column) or regression (for one numeric column).
- EZR’s active learner, does the same multi-objective task, but with
very few peeks at the goal y values.
- Why? Since it usually very cheap to get
Xbut very expensive to getY.
- Why? Since it usually very cheap to get
For testing purposes here, all the examples explored here come with all their \(Y\) values.
- We just take great care in the code to record how many rows we use to look up \(Y\) labels.
3 AI Notes
3.1 Aggregation Functions
To sort the data, all the goals have to be aggregated into one function. Inspired by the MOEA/D algorithm1, EZR uses the Chebyshev function that returns the max difference between the goal values and the best possible values. The rows shown above are sorted top to bottom, least to most Chebyshev values (so the best rows, with smallest Chebyshev, are shown at top).
Chebyshev is very simple to code. We assume a lost of goal columns
self.cols.y each of which knows:
- its column index
col.at - How to
normalize values 0..1, min..max usingcol.norm(x) - What is the best value
col.goal:- For goals to minimize, like “Lbs-”,
goal=0. - For goals to maximize, like “Mpg+”,
goal=1.
- For goals to minimize, like “Lbs-”,
@of("Compute Chebyshev distance of one row to the best `y` values.")
def chebyshev(self:DATA,row:row) -> number:
return max(abs(col.goal - col.norm(row[col.at])) for col in self.cols.y)
@of("Returns 0..1 for min..max.")
def norm(self:NUM, x) -> number:
return x if x=="?" else ((x - self.lo) / (self.hi - self.lo + 1E-32))When we say “rank DATA”, we mean sort all the rows by their Chebyshev distance:
@of("Sort rows by the Euclidean distance of the goals to heaven.")
def chebyshevs(self:DATA) -> DATA:
self.rows = sorted(self.rows, key=lambda r: self.chebyshev(r))
return self3.2 Active Learning Buzzwords
e.g.
Before:
y y y n n : Y (dependent, many missing values)
1 2 3 4 5 6 7 8 9 10 : X (independent, most fully known)
So:
x2 x2 : AQ1: explore (usual initial tactic)
x1 : AQ2: exploit (once we know where the good stuff is)
x3 x3 x3 x3 : AQ3: representativeiness
x4 x4 x4 x4 : AQ4: diversity
x5 x5 x5 x5 : AQ5: perversity (to boldly go where no one has gone before)| words | note |
|---|---|
| explore | looking for places that can change our
mind In the above, try x=6 |
| exploit | go to where things look best In the above, try x=(2,3,4) (since that is where things look best). A.k.a. greedy search |
| adaptive | moving from explore to exploit as the reasoning continues |
| acquisition functions | the thing that tells us to explore/exploit/whatever |
| informativeness | a.k.a. exploit. Go where its looks good. |
| representiveness | equal parts in all regions e.g. x=2,3,4 half the time and x=9,10 half the time |
| diversity | ignore the Y values and sample randomly and widely |
| perversity (my term) | go where you ain’t gone before. |
| cold-start | no prior knowledge |
| warm-start | some prior (steam-based is usually warm-start) |
| population-based | objective function knowm, we (e.g.) surf its gradients looking for cool pleases to study next |
| surrogate-based | objective function unknown so we build an approximation from the available data |
| pool-based | surrogate-based. have knowledge of lots of independent variables |
| stream-based | surrogate based. have a (small) window of next examples, after which we wills ee another and and anouter. This is usually a warm-start tactic |
| model-query synthesis | surrogate or population-based. look at model so far, infer where to try next. Kind an extreme version of explore. May include e.g. feature weighting to decide what to ignore |
In most of my current experiments:
- surrogate-based
- usually cold-start
- but work over summer by grad students suggests that diversity sampling (to create a warm start) means that exploit defeats adaptive and/or explore
- in batch-mode (when we read all the data) we are pool-based
- area open for research: stream-based
3.3 Configuration
Other people define their command line options separate to the settings. That is they have to define all those settings twice
This code parses the settings from the doc string (see the SETTINGS class). So the help text and the definitions of the options can never go out of sync.
3.4 Classes
This code has only a few main classes: SETTINGS, DATA, COLS, NUM, SYM
- SETTINGS handles the config settings.
- The code can access these settings via the
thevariable (sothe = SETTINGS()).
- The code can access these settings via the
- NUM, SYM, COL (the super class of NUM,SYM). These classes summarize
each column.
- NUMs know mean and standard deviation (a measure of average distance
of numbers to the mean)
- \(\sigma=\sqrt{\frac{1}{N-1} \sum_{i=1}^N (x_i-\overline{x})^2}\)
- SYMs know mode (most common symbol) and entropy (a measure of how
often we see different symbols)
- entropy = \(-\sum_{i=1}^n p(x_i) \log_2 p(x_i)\)
- Mean and mode are both measures of central tendency
- Entropy and standard deviation are measures of confusion.
- The lower their values, the more likely we can believe in the central tendency
- NUMs know mean and standard deviation (a measure of average distance
of numbers to the mean)
- DATA stores
rows, summarized incols(columns). - COLS is a factory that takes a list of names and creates the
columns.
- All the columns are stored in
all(and some are also stored inxandy).
- All the columns are stored in
@dataclass
class COLS:
names: list[str] # column names
all : list[COL] = LIST() # all NUMS and SYMS
x : list[COL] = LIST() # independent COLums
y : list[COL] = LIST() # dependent COLumns
klass: COL = NoneTo build the columns, COLS looks at each name’s a,z
(first and last letter).
- e.g.
['Clndrs', 'Volume', 'HpX', 'Model','origin', 'Lbs-', 'Acc+', 'Mpg+']
def __post_init__(self:COLS) -> None:
for at,txt in enumerate(self.names):
a,z = txt[0],txt[-1]
col = (NUM if a.isupper() else SYM)(at=at, txt=txt)
self.all.append(col)
if z != "X":
(self.y if z in "!+-" else self.x).append(col)
if z=="!": self.klass = col
if z=="-": col.goal = 03.5 Smarts
3.5.1 Bayes classifier
When you have labels, a simple and fast technique is:
- Divide the rows into different labels,
- Collect statistics independently for each label. For us, this means building one DATA for each label.
- Then ask how likely is a row to belong to each DATA?
- Internally, this will become a recursive call asking how likely am I to belong to each x column of the data
The probability of x belong to a column is pretty
simple:
@of("How much a SYM likes a value `x`.")
def like(self:SYM, x:any, prior:float) -> float:
return (self.has.get(x,0) + the.m*prior) / (self.n + the.m)
@of("How much a NUM likes a value `x`.")
def like(self:NUM, x:number, _) -> float:
v = self.sd**2 + 1E-30
nom = exp(-1*(x - self.mu)**2/(2*v)) + 1E-30
denom = (2*pi*v) **0.5
return min(1, nom/(denom + 1E-30))The likelihood of a row belonging to a label, given new evidence, is the prior probability of the label times the probability of the evidence. For example, if we have three oranges and six apples, then the prior on oranges is 33%.
For numerical methods reasons, we add tiny counts to the attribute and class frequencies (\(k=1,m=2\)) and treat all the values as logarithms (since these values can get real small, real fast)
@of("How much DATA likes a `row`.")
def loglike(self:DATA, r:row, nall:int, nh:int) -> float:
prior = (len(self.rows) + the.k) / (nall + the.k*nh)
likes = [c.like(r[c.at], prior) for c in self.cols.x if r[c.at] != "?"]
return sum(log(x) for x in likes + [prior] if x>0)For more notes on Bayes, see this example
3.5.2 Active Learner
The active learner uses a Bayes classifier to guess the likelihood that an unlabeled example should be labeled next.
- All the unlabeled data is split into a tiny
doneset and a much largertodoset - All the
dones are labeled, then ranked, then divided into \(\sqrt{N}\) best and \(1-\sqrt{N}\) rest. - Some sample of the
todos are the sorted by their probabilities of being best (B), not rest (R)- The following code uses \(B-R\)
- But these values ore logs so this is really \(B/R\).
- The top item in that sort is then labelled and move to done.
- And the cycle repeats
@of("active learning")
def activeLearning(self:DATA, score=lambda B,R: B-R, generate=None, faster=True ):
def ranked(rows): return self.clone(rows).chebyshevs().rows
def todos(todo):
if faster: # Apply our sorting heuristics to just a small buffer at start of "todo"
# Rotate back half of the buffer to end of list. Shift left to fill in the gap.
n = the.buffer//2
return todo[:n] + todo[2*n: 3*n], todo[3*n:] + todo[n:2*n]
else: # Apply our sorting heustics to all of todo.
return todo,[]
def guess(todo:rows, done:rows) -> rows:
cut = int(.5 + len(done) ** the.cut)
best = self.clone(done[:cut]) # --------------------------------------------------- [2]
rest = self.clone(done[cut:])
a,b = todos(todo)
if generate: # don't worry about this bit
return self.neighbors(generate(best,rest), a) + b # ----------------------------- [3]
else:
key = lambda r: score(best.loglike(r, len(done), 2), rest.loglike(r, len(done), 2))
return sorted(a, key=key, reverse=True) + b # ----------------------------------- [3]
def loop(todo:rows, done:rows) -> rows:
for k in range(the.Last - the.label):
if len(todo) < 3 : break
top,*todo = guess(todo, done)
done += [top] # ------------------------------------------------------------ [3]
done = ranked(done)
return done
return loop(self.rows[the.label:], ranked(self.rows[:the.label])) #------------------- [1]The default configs here is the.label=4 and
the.Last=30; i.e. four initial evaluations, then 26 evals
after that.
TL;DR: to explore better methods for active learning:
- change the
guess()function - and do something, anything with the unlabeled
todoitems (looking only at the x values, not the y values).
4 SE notes:
Programming idioms are low-level patterns specific to a particular programming language. For example, see decorators which are a Python construct
Idioms are small things. Bigger than idioms are patterns : elegant solution to a recurring problem. Some folks have proposed extensive catalogs of patterns. These are worth reading. As for me, patterns are things I reuse whenever I do development in any languages. This code uses many patterns (see below).
Even bigger than patterns are architectural style is a high-level conceptual view of how the system will be created, organized and/or operated.
4.1 Architectural Styles
This code is pipe and filter. It can accept code from
some prior process or if can read a file directly. These two calls are
equivalent (since “-” denotes standard input). This pile-and-filter
style is important since
python3.13 -B ezr.py -t ../moot/optimize/misc/auto93.csv -e _mqs
cat ../moot/optimize/misc/auto93.csv | python3.13 -B ezr.py -t - -e _mqs(Aside: to see how to read from standard input or a file, see
def csv in the source code.)
Pipe-and-filters are a very famous architectural style:
Doug McIlroy, Bell Labs, 1986: “We should have some ways of coupling programs like garden hose…. Let programmers screw in another segment when it becomes necessary to massage data in another way…. Expect the output of every program to become the input to another, as yet unknown, program. Don’t clutter output with extraneous information.”
Pipes changed the whole idea of UNIX:
- Implemented in 1973 when (“in one feverish night”, wrote McIlroy) by Ken Thompson.
- “It was clear to everyone, practically minutes after the system came up with pipes working, that it was a wonderful thing. Nobody would ever go back and give that up if they could.”
- The next day”, McIlroy writes, “saw an unforgettable orgy of one-liners as everybody joined in the excitement of plumbing.”
For example, my build files have help text after a ##
symbol. The following script prints a little help text describing that
build script. It is a pipe between grep, sort, and awk Note the
separation of concerns (which means that now our task divides into tiny
tasks, each of which can be optimized separately):
grephandles feature extraction from the build file;sortrearranges the contents alphabeticallygawkhandles some formatting trivia.
help: ## print help
printf "\n#readme\nmake [OPTIONS]\n\nOPTIONS:\n"
grep -E '^[a-zA-Z_\.-]+:.*?## .*$$' $(MAKEFILE_LIST) \
| sort \
| awk 'BEGIN {FS = ":.*?## "}\
{printf " \033[36m%-10s\033[0m %s\n", $$1, $$2}'This produces:
% make help
#readme
make [OPTIONS]
OPTIONS:
README.md update README.md, publish
help print help
push commit to Git. Pipes are seen in scripting environments and are used a lot in modern languages.e .g. in “R”. Compare how many gallons of gas I would need for a 75 mile trip among 4-cylinder cars:
library(dplyr) # load dplyr for the pipe and other tidy functions
data(mtcars) # load the mtcars dataset
df <- mtcars %>% # take mtcars. AND THEN...
filter(cyl == 4) %>% # filter it to four-cylinder cars, AND THEN...
select(mpg) %>% # select only the mpg column, AND THEN...
mutate(car = row.names(.), # add a column for car name and # gallons used on a 75 mile trip
gallons = mpg/75)4.1.1 Social patterns: Coding for Teams
This code is poorly structured for team work:
- For teams, better to have tests in separate file(s)
- If multiple test files, then many people can write their own special tests
- When tests are platform-dependent, it is good to be able to modify the tests without modifying the main thing;
- For teams, better to have code in multiple files:
- so different people can work in separate files (less chance of edit conclusions)
- This code violates known Python formatting standards
(PEP 8) which is supported by so many tools; e.g. Black and various
tools in VScode
- Consider to have commit hooks to re-format the code to something more usual
- My use of the of is highly non-standard. Teams would probably want to change that.
4.1.2 Pattern: All code need doco
Code has much auto-documentation - functions have type hints and doc strings - help string at front (from which we parse out the config) - worked examples (at back)
For examples of methods for adding that doco, see
make help command above.
4.1.3 Pattern: All code needs tests
Maurice Wilkes recalled the exact moment he realized the importance of debugging: “By June 1949, people had begun to realize that it was not so easy to get a program right as had at one time appeared. It was on one of my journeys between the EDSAC room and the punching equipment that the realization came over me with full force that a good part of the remainder of my life was going to be spent in finding errors in my own programs.”
Half the time of any system is spent in testing. Lesson: don’t code it the night before.
Testing is more than just “finding bugs”. Test suites are a great way to communicate code and to offer continuous quality assurances.
- Tests offer little lessons on how to use the code.
- Teams sharing code can rerun the tests, all the time, to make sure
their new code does not break old code.
- Caveat: that only works if the tests are fast unit tests.
Exr.py has tests (worked examples at back); about a quarter of the code base
- any method eg.method can be called from the command line using.
e.g. to call egs.mqs:
- python3 ezr.py -e mqs
There is much more to say about tests. That is another story and will be told another time.
4.1.4 Pattern: Configuration
- All code has config settings. Magic numbers should not be buried in the code. They should be adjustable from the command line (allows for easier experimentation).
- BTW, handling the config gap is a real challenge. Rate of new config grows much faser than rate that people understanding those options2. Need active learning To explore that exponentially large sapce!
4.1.5 Pattern: Function vs Object-Oriented
Object-oriented code is groups by class. But some folks doubt that approach:
My code is function-oriented: methods are grouped via method name (see the of decorator). This makes it easier to teach retlated concepts (since the concepts are together in the code).
Me doing this way was inspired by some words of Donald Knth who pointed out that the order with which we want to explains code may not be the same the order needed by the compiler. So he wrote a “tangle” system where code and comments, ordered for explaining, was rejigged at load time into what the compiler needs. I found I could do a small part of Knthu’s tangle with a 5 line decorator.
4.1.6 Pattern: Short functions
- Robert Martin:
- Functions should do one thing. They should do it well. They should do it only.
- Smaller functions are mostly robust, easy to read and maintain.
- So the first rule of functions is that they should be small.
- How small? Some say five lines
- The second rule of functions is that they should be smaller than that.
4.1.7 Pattern: DRY, not WET
- WET = Write everything twice.
- Other people define their command line options separate to the
settings.
- That is they have to define all those settings twice
- Other people define their command line options separate to the
settings.
- DRY = Dont’ repeat yourself.
- This code parses the settings from the doc string (see the SETTINGS class)
- That is, my settings options are DRY.
- When to be DRY
- If it only occurs once, then ok.
- If you see it twice, just chill. You can be a little WET
- if you see it thrice, refactor so “it” is defined only once, then reused elsewhere
4.1.8 Pattern: Little Languages
- Operate policy from mechanisms; i.e. the spec from the machinery that uses the spec
- Allows for faster adaption
- In this code:
- The column names is a “little language” defining objective problems.
- Parsing doc string makes that string a little language defining setting options.
- The SETTINGS class uses regular expressions to extract the settings
- regular expressions are other “little languages”
- Another “not-so-little” little language: Makefiles handles dependencies and updates
4.1.8.1 Little Languages: Make
Make files let us store all our little command line tricks in one convenient location. Make development was started by Stuart Feldman in 1977 as a Bell Labs summer intern (go interns!). It worthy of study since it is widely available on many environments.
There are now many build tools available, for example Apache ANT, doit, and nmake for Windows. Which is best for you depends on your requirements, intended usage, and operating system. However, they all share the same fundamental concepts as Make.
Make has “rules” and the rules have three parts: target, dependents (which can be empty), and code to build the target from the dependents. For example, the following two rules have code that simplifies our interaction with git.
- The command
make pullupdates the local files (no big win here) - The command
make pushusesreadto collect a string explaining what a git commit is for, then stages the commit, then makes the commit, then checks for things that are not committed.
pull : ## download
git pull
push : ## save
echo -en "\033[33mWhy this push? \033[0m"; read x; git commit -am "$$x"; git push; git statusFor rules with dependents, the target is not changed unless there are
newer dependents. For example, here is the rule that made this file.
Note that this process needs a bunch of scripts, a css file etc. Make
will udpate docs/%.html if ever any of those dependents
change.
docs/%.html : %.py etc/py2html.awk etc/b4.html docs/ezr.css Makefile ## make doco: md -> html
echo "$< ... "
gawk -f etc/py2html.awk $< \
| pandoc -s -f markdown --number-sections --toc --toc-depth=5 \
-B etc/b4.html --mathjax \
--css ezr.css --highlight-style tango \
--metadata title="$<" \
-o $@ This means that make docs/*.html will update all the
html files at this site. And if we call this command twice, the second
call will do nothing at all since docs/%.html is already up
to date. This can save a lot of time during build procedures.
The makefile for any particular project can get very big. Hence, it s
good practice to add an auto document rule (see the
make help command, above). Note that this is an example of
the all code needs doco pattern (also described above).
4.1.8.2 Little Languages: Regular Expressions
- Example of a “little language”
- Used here to extract settings and their defaults from the
__doc__string- in SETTINGS, using
r"\n\s*-\w+\s*--(\w+).*=\s*(\S+)(a leading “r” tells Python to define a regular expression)
- in SETTINGS, using
- Other, simpler Examples:
- leading white space
^[ \t\n]*(spare brackets means one or more characters; star means zero or more) - trailing white space
[ \t\n]*$(dollar sign means end of line) - IEEE format number
^[+-]?([0-9]+[.]?[0-9]*|[.][0-9]+)([eE][+-]?[0-9]+)?$(round brackets group expressions; vertical bar denotes “or”; “?” means zero or one)
- leading white space
- Beautiful example, guessing
North Amererican Names using regualr expressions
- For a cheat sheet on regular expressions, see p64 of that article)
- For source code, see gender.awk
- For other articles on regular expressions:
- At their core, they can be surprisingly simple
- Fantastic article: Regular Expression Matching Can Be Simple And Fast,
4.2 Validation
Validation procedures are designed to counter two anti-patterns in
learning. For example, the xval function (described below)
randomly shuffles the order of the training data (to handle order
effects) then splits the data into bins (where one bin is for testing
and the others are for training):
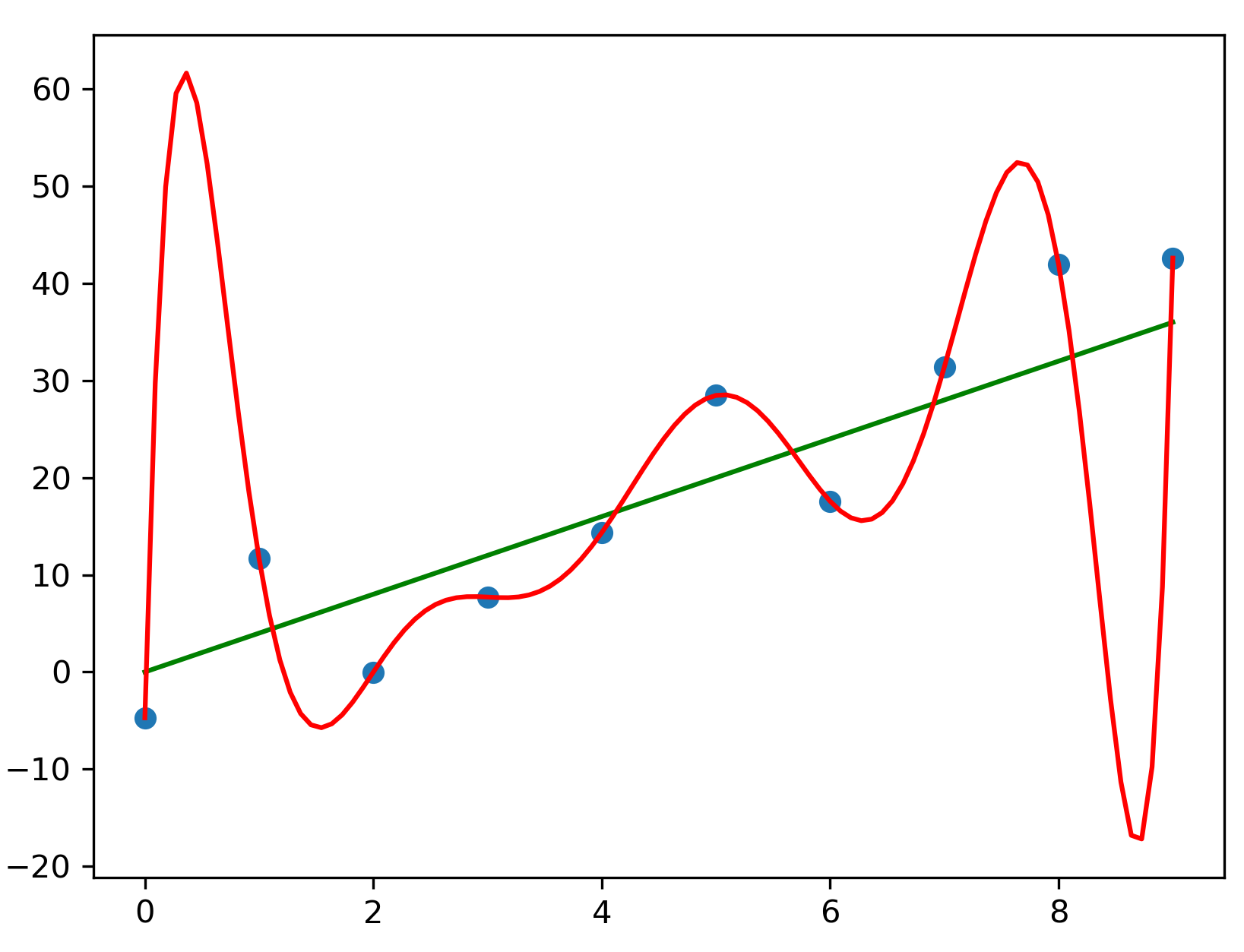
- Over-fitting is when a learner learns too much from the
training data.
- Rather than focus on the big picture, over-fitting means that models are built from minor details that many never repeat in the future.
- Over-fitting explains the effect where a learner performs well on the training data, but badly on future data.Learners should be trained on some data, then tested on some other data.
- To counter over-fitting, is it recommended to test a model on some hold-out data not used in training.
- Order effects refer to differences in learning outcomes due
to the order in which material is presented.
- e.g. Suppose a hospital sends you a data dump where all the women
come before all the men.
- On that data, an incremental learner might quickly achieve competency on certain conditions, while never seeing other illnesses.
- To counter order effects, it is recommended to randomly shuffle the order of data before dividing in into train and test.
- e.g. Suppose a hospital sends you a data dump where all the women
come before all the men.
- Learning variability: If you run a learner N times on
different training data, you can get N different models
- So to check if you have learned a useful model, or just some fluke based on quirks in your training data, it is recommended to run the experiments N times and look for results that are stable across most of the repeats.
Another validation scheme, suitable for streaming data, is to train on past data the test on some limited buffer into the future:
- Eg. train on the last 12 months of data and test on the next month
- then jump to month+1 an repeat.
4.3 Python Idioms
4.3.1 Magic Methods
Dunder = double underscore = “__”
Dunders define certain core functions; e.g.
__init__(for initialization)- or
__repr__to return a printed representation of an object. i i- or__dict__which is the magic internal variable most Python classes to hold instance variables
For example, here’s a quick and dirty hold-all class that can print its own cotents.
class o:
__init__ = lambda i,**d : i.__dict__.update(d)
__repr__ = lambda i : i.__class__.__name__+str(i.__dict__)
the = o(
seed = 1234567891,
round = 2,
stats = o(cohen=0.35,
cliffs=0.195, #border between small=.11 and medium=.28
bootstraps=512,
confidence=0.05))With the above, now our code can say things like
the.stats.cohen.
If you want, you can even redefine +
(__add__) or = (__eq__):
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __eq__(self, other):
return self.x == other.x and self.y == other.y
p1 = Point(1, 2)
p2 = Point(1, 2)
p3 = Point(3, 4)
print(p1 == p2) # True
print(p1 == p3) # FalseThere are so many other dunders:
| Magic Method | Description |
|---|---|
__init__ |
Initializes a new instance of a class. |
__del__ |
Called before an object is destroyed. |
__repr__ |
Returns an official string representation of an object. |
__str__ |
Returns a string representation of an object. |
__len__ |
Returns the length of an object. |
__getitem__ |
Gets an item from an object using indexing. |
__setitem__ |
Sets an item in an object using indexing. |
__delitem__ |
Deletes an item from an object using indexing. |
__iter__ |
Returns an iterator object. |
__next__ |
Returns the next item from an iterator. |
__contains__ |
Checks if an object contains a value. |
__call__ |
Allows an object to be called like a function. |
__eq__ |
Checks if two objects are equal. |
__ne__ |
Checks if two objects are not equal. |
__lt__ |
Checks if one object is less than another. |
__le__ |
Checks if one object is less than or equal to another. |
__gt__ |
Checks if one object is greater than another. |
__ge__ |
Checks if one object is greater than or equal to another. |
__add__ |
Adds two objects. |
__sub__ |
Subtracts one object from another. |
__mul__ |
Multiplies two objects. |
__truediv__ |
Divides one object by another. |
__floordiv__ |
Performs floor division on two objects. |
__mod__ |
Returns the remainder of division. |
__pow__ |
Raises one object to the power of another. |
__and__ |
Performs bitwise AND on two objects. |
__or__ |
Performs bitwise OR on two objects. |
__xor__ |
Performs bitwise XOR on two objects. |
__lshift__ |
Performs left bitwise shift on an object. |
__rshift__ |
Performs right bitwise shift on an object. |
__neg__ |
Returns the negation of an object. |
__pos__ |
Returns the positive value of an object. |
__abs__ |
Returns the absolute value of an object. |
__invert__ |
Returns the bitwise inversion of an object. |
__round__ |
Rounds an object to a given number of digits. |
__bool__ |
Returns the boolean value of an object. |
__hash__ |
Returns the hash value of an object. |
__enter__ |
Called when entering a context (with statement). |
__exit__ |
Called when exiting a context (with statement). |
4.3.2 Data classes
This code uses dataclasses. These are a great shorthand method for defining classes. All dataclasses supply their own init and pretty-print methods. For example, here is a class with dataclasses
class Person():
def __init__(self, name='Joe', age=30, height=1.85, email='joe@dataquest.io'):
self.name = name
self.age = age
self.height = height
self.email = emailBt with data classes:
from dataclasses import dataclass
@dataclass
class Person():
name: str = 'Joe'
age: int = 30
height: float = 1.85
email: str = 'joe@dataquest.io'
print(Person(name='Tim', age=1000))
==> Person(name='Tim', age=1000, height=1.85, email='joe@dataquest.io')4.3.3 Type hints
In other languages, types are taken very seriously and are the basis for computation.
The Python type system was a bolt-on to later versions of the language. Hence, it is not so well-defined.
But it is a great documentation tools since they let the programmer tell the reader what goes in and out of their function.
Firstly, you can define your own types. For example,
classes stores rows of data about (e.g.) dogs and cats in a
dictionary whose keys are “dogs” and “cats”
data= dict(dogs=[['ralph','poodle',2021],['benhi','labrador',2022]]
cats=[['miss meow', 'ginger' 2020], etc])We can define these classes as follows:
from __future__ import annotations
from typing import Any as any
from typing import List, Dict, Type, Callable, Generator
number = float | int #
atom = number | bool | str # and sometimes "?"
row = list[atom]
rows = list[row]
classes = dict[str,rows] # `str` is the class nameThen we can define a classifier as something that accepts
classes and a new row and returns a guess as to what class
it belongs to:
def classifier(data: classes, example: row) -> str:
...Or, for a nearest neighbor classifier, we can define a function that
sorts all the rows by the distance to some new row called
row1 as follows (and here, the nearest neighbor to
row1 is the first item in the returned row.
def neighbors(self:DATA, row1:row, rows:rows=None) -> rows:
return sorted(rows, key=lambda row2: self.dist(row1, row2))4.3.4 Abstraction
(Note that the following abstractions are available in many languages. So are they a pattern? Or an idiom? I place them here since the examples are Python-specific.)
4.3.4.1 Exception Handling
Exception handling in Python allows you to handle errors gracefully
without crashing your program. The basic structure involves
try, except, else, and
finally blocks.
E.g. suppose you want a string to be a float, int, bool and if that
all fails, be a string. The ast module has a method
literal_eval that can handle most of that. So if it fails,
we just return a string
import ast
def coerce(s:str) -> atom:
"Coerces strings to atoms."
try: return ast.literal_eval(s)
except Exception: return sFun fact: I once spent an afternoon trying to debug something where
everything had turned to strings. Turns out, I’d forgotten to
import ast so the try part of the above was
always failing.
4.3.4.2 Iterators
Iterators are things that do some set up, yield one thing, then wait till asked, then yield one other hing, then wait till asked, then yield another other thing, etc. They are offer a simple interface to some under-lying complex process.
For example, my code’s csv function opens a file,
removes spaces from each line, skips empty lines, splits lines on a
comma, then coerces each item in the row to some Python type. Note that
this function does not return, but it
yields.
def csv(file) -> Generator[row]:
infile = sys.stdin if file=="-" else open(file)
with infile as src:
for line in src:
line = re.sub(r'([\n\t\r ]|#.*)', '', line)
if line: yield [coerce(s.strip()) for s in line.split(",")]
# def coerce(s:str) -> atom: (defined above)We can call it this way (note the simplicity of the interface)
for row in csv(fileName):
# row is now something like [4,86,65,80,3,2110,17.9,50]
doSomethhing(fileName)Here’s another that implements a cross validation test rig where learners train on some data, then test on some hold-out.
- To avoid learn things due to trivial orderings in the file, we shuffle the whole list
- The shuffled list is then split into
nbins. - For each bin, yield it as the
testand all the other bins asrest. - Optionally, only use some random sample of train, train
The following is an m-by-n cross val. That is, from m
shuffling, yield n train,test set pairs. For the default
values (m=n=5) this yields 25 train,test set pairs.
def xval(lst:list, m:int=5, n:int=5, some:int=10**6) -> Generator[rows,rows]:
for _ in range(m):
random.shuffle(lst) # -------------------------------- [1]
for n1 in range (n):
lo = len(lst)/n * n1 # ------------------------------- [2]
hi = len(lst)/n * (n1+1)
train, test = [],[]
for i,x in enumerate(lst):
(test if i >= lo and i < hi else train).append(x)
train = random.choices(train, k=min(len(train),some)) # --- [4]
yield train,test #---------------------------------------- [3]4.3.5 Comprehensions
This code makes extensive use of comprehensions . E.g. to find the middle of a cluster, ask each column for its middle point.
@of("Return central tendency of a DATA.")
def mid(self:DATA) -> row:
return [col.mid() for col in self.cols.all]
@of("Return central tendency of NUMs.")
def mid(self:NUM) -> number: return self.mu
@of("Return central tendency of SYMs.")
def mid(self:SYM) -> number: return self.modeComprehensions can be to filter data:
>>> [i for i in range(10) if i % 2 == 0]
[0, 2, 4, 6, 8]Here’s one for loading tab-separated files with optional comment lines starting with a hash mark:
data = [line.strip().split("\t") for line in open("my_file.tab") \
if not line.startswith('#')]e.g. here are two examples of an implicit iterator in the argument to
sum:
@of("Entropy = measure of disorder.")
def ent(self:SYM) -> number:
return - sum(n/self.n * log(n/self.n,2) for n in self.has.values())
@of("Euclidean distance between two rows.")
def dist(self:DATA, r1:row, r2:row) -> float:
n = sum(c.dist(r1[c.at], r2[c.at])**the.p for c in self.cols.x)
return (n / len(self.cols.x))**(1/the.p)E.g here we
- Use dictionary comprehensions, make a dictionary with one emery list per key,
- Using list comprehensions, add items into those lists
- Finally, using dictionary comprehensions, return a dictionary with one prediction per col.
@of("Return predictions for `cols` (defaults to klass column).")
def predict(self:DATA, row1:row, rows:rows, cols=None, k=2):
cols = cols or self.cols.y
got = {col.at : [] for col in cols} -- [1]
for row2 in self.neighbors(row1, rows)[:k]:
d = 1E-32 + self.dist(row1,row2)
[got[col.at].append( (d, row2[col.at]) ) for col in cols] -- [2]
return {col.at : col.predict( got[col.at] ) for col in cols} -- [3]4.3.6 Decorators
- Decorated are functions called at load time that manipulate other functions.
- E.g. the
ofdecorator lets you define methods outside of a function. Here it is used to group together themid(middle) anddiv(diversity) functions.- The
mid(ddle) of a NUMeric and a SYMbol column are their means and modes. - As to
DATA, thsee hold rows which are summarized incols. Themidof those rows is themidof the summary for each column.
- The
def of(doc):
def doit(fun):
fun.__doc__ = doc
self = inspect.getfullargspec(fun).annotations['self']
setattr(globals()[self], fun.__name__, fun)
return doit
@of("Return central tendency of a DATA.")
def mid(self:DATA) -> row:
return [col.mid() for col in self.cols.all]
@of("Return central tendency of NUMs.")
def mid(self:NUM) -> number: return self.mu
@of("Return central tendency of SYMs.")
def mid(self:SYM) -> number: return self.mode
@of("Return diversity of a NUM.")
def div(self:NUM) -> number: return self.sd
@of("Return diversity of a SYM.")
def div(self:SYM) -> number: return self.ent()5 Try it for yourself
5.1 Fork a repo
- Go to https://github.com/timm/ezr/
- Hit the “fork” button (near top, rhs)
- On the next screen, find the checkbox hat says “only fork main brancch”. Unselect that option
- Go to the new repo, Find the green “code” button. Create a codespace on main.
5.2 Get Python3.13
Make sure you are running Python3.13. On Linux and Github code spaces, that command is
sudo apt update -y; sudo apt upgrade -y; sudo apt install software-properties-common -y; sudo add-apt-repository ppa:deadsnakes/ppa -y ; sudo apt update -y ; sudo apt install python3.13 -yNow check you have python3.13
python3.13 -B --version5.3 Try one run
cd /workspaces/ezr
git checkout 24Aug14
python3.13 -B ezr.py -t data/misc/auto93.csv -e _mqs5.4 Try a longer run
This takes a new minutes, writes output t
cd /workspaces/ezr
Here=$PWD
cd data/optimize/process
mkdir -p ~/tmp/mqs
for i in *.csv ; do $Here/ezr.py -D -e _mqs -t $i | tee ~/tmp/mqs/$i ; done5.5 Write your own extensions
Here’s a file extend.py in the same directory as
ezr.py
import sys,random
from ezr import the, DATA, csv, dot
def show(lst):
return print(*[f"{word:6}" for word in lst], sep="\t")
def myfun(train):
d = DATA().adds(csv(train))
x = len(d.cols.x)
size = len(d.rows)
dim = "small" if x <= 5 else ("med" if x < 12 else "hi")
size = "small" if size< 500 else ("med" if size<5000 else "hi")
return [dim, size, x,len(d.cols.y), len(d.rows), train[17:]]
random.seed(the.seed) # not needed here, but good practice to always take care of seeds
show(["dim", "size","xcols","ycols","rows","file"])
show(["------"] * 6)
[show(myfun(arg)) for arg in sys.argv if arg[-4:] == ".csv"]On my machine, when I run …
python3.13 -B extend.py data/optimize/[chmp]*/*.csv > ~/tmp/tmp
sort -r -k 1,2 ~/tmp/tmp… this prints some stats on the data files:
dim size xcols ycols rows file
------ ------ ------ ------ ------ ------
small small 4 3 398 misc/auto93.csv
small small 4 2 259 config/SS-H.csv
small small 3 2 206 config/SS-B.csv
small small 3 2 196 config/SS-G.csv
small small 3 2 196 config/SS-F.csv
small small 3 2 196 config/SS-D.csv
small small 3 1 196 config/wc+wc-3d-c4-obj1.csv
small small 3 1 196 config/wc+sol-3d-c4-obj1.csv
small small 3 1 196 config/wc+rs-3d-c4-obj1.csv
small med 5 2 1080 config/SS-I.csv
small med 3 2 1512 config/SS-C.csv
small med 3 2 1343 config/SS-A.csv
small med 3 2 756 config/SS-E.csv
small hi 5 3 10000 hpo/healthCloseIsses12mths0011-easy.csv
small hi 5 3 10000 hpo/healthCloseIsses12mths0001-hard.csv
med small 9 1 192 config/Apache_AllMeasurements.csv
med med 11 2 1023 config/SS-P.csv
med med 11 2 1023 config/SS-L.csv
med med 11 2 972 config/SS-O.csv
med med 10 2 1599 misc/Wine_quality.csv
med med 9 3 500 process/pom3d.csv
med med 6 2 3840 config/SS-S.csv
med med 6 2 3840 config/SS-J.csv
med med 6 2 2880 config/SS-K.csv
med med 6 1 3840 config/rs-6d-c3_obj2.csv
med med 6 1 3840 config/rs-6d-c3_obj1.csv
med med 6 1 2880 config/wc-6d-c1-obj1.csv
med med 6 1 2866 config/sol-6d-c2-obj1.csv
med hi 11 2 86058 config/SS-X.csv
med hi 9 3 20000 process/pom3c.csv
med hi 9 3 20000 process/pom3b.csv
med hi 9 3 20000 process/pom3a.csv
hi small 22 4 93 process/nasa93dem.csv
hi med 38 1 4653 config/SQL_AllMeasurements.csv
hi med 21 2 4608 config/SS-U.csv
hi med 17 5 1000 process/coc1000.csv
hi med 17 3 864 config/SS-M.csv
hi med 16 1 1152 config/X264_AllMeasurements.csv
hi med 14 2 3008 config/SS-R.csv
hi med 14 1 3456 config/HSMGP_num.csv
hi med 13 3 2736 config/SS-Q.csv
hi hi 23 4 10000 process/xomo_osp2.csv
hi hi 23 4 10000 process/xomo_osp.csv
hi hi 23 4 10000 process/xomo_ground.csv
hi hi 23 4 10000 process/xomo_flight.csv
hi hi 17 2 53662 config/SS-N.csv
hi hi 16 2 65536 config/SS-W.csv
hi hi 16 2 6840 config/SS-V.csv
hi hi 12 2 5184 config/SS-T.csvTry modifying the output to add columns to report counts of the number of symbolic and numeric columns.
Q. Zhang and H. Li, “MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition,” in IEEE Transactions on Evolutionary Computation, vol. 11, no. 6, pp. 712-731, Dec. 2007, doi: 10.1109/TEVC.2007.892759.↩︎